Data Source Status and Bulk Actions
DRUID offers intuitive data source statuses and bulk actions based on the data source type and status.
Data source status transitions
This section explains the status transitions for unstructured data sources.
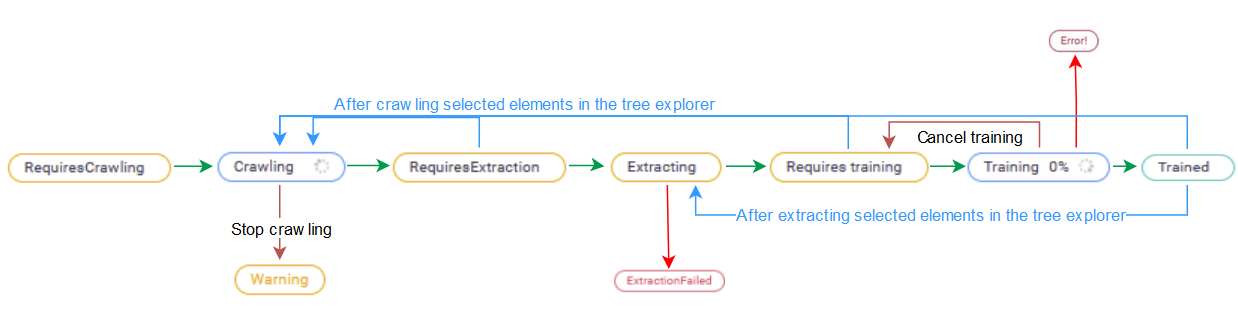
File repository
The diagram below illustrates the status transitions for File Repository data sources.
![]()
Website, SharePoint, Network shared drive
The following diagram shows the status transitions for Website, SharePoint, and Network Shared Drive data sources.
Data source status description
The table below provides brief descriptions of the statuses for unstructured data sources.
|
Status |
Data source type |
Description |
|---|---|---|
| New | File repository | The status given to the data source after creation or after all files have been deleted from the data source (via the bulk delete action). |
| Requires Crawling | all except File repository | The KB engine requires to discover the web pages from the given Content Location (URL) / website / Uri based on the specified crawling policy. |
| Crawling | all except File repository |
The crawler identifies the web pages from the given Content Location (URL) / website / Uri based on the specified crawling policy, and adds them to the data source index. The web pages appear in the tree explorer. |
| Warning | all except File repository | The crawling failed. |
| Requires Extraction | all | The data has been uploaded in the data source but it requires extraction. |
| Extracting | all | The KB Engine is extracting the data from the uploaded files / crawled web pages. |
| Extraction failed | all | One or more documents / web pages failed extraction. |
|
Requires Training |
all |
The data has been successfully extracted but the data source / KB requires training. NOTE: In DRUID 7.8 and higher, you can train the KB even if one or more documents failed extraction.
|
|
Training |
all |
The NLP model is indexing the articles from the data source. |
|
Error |
all |
An error occurred on data source indexing. |
|
Trained |
all |
The AI Agent NLP model has been successfully trained to understand the data from the data source or from all data sources based on the selected train action. |
Bulk actions
You can perform bulk actions on data sources:
- Go to the Extracted Paragraphs tab.
- Click the dots in the upper-left corner.
The available bulk actions depend on:
- The data source type
- The data source status
- The selection of multiple elements in the tree explorer.
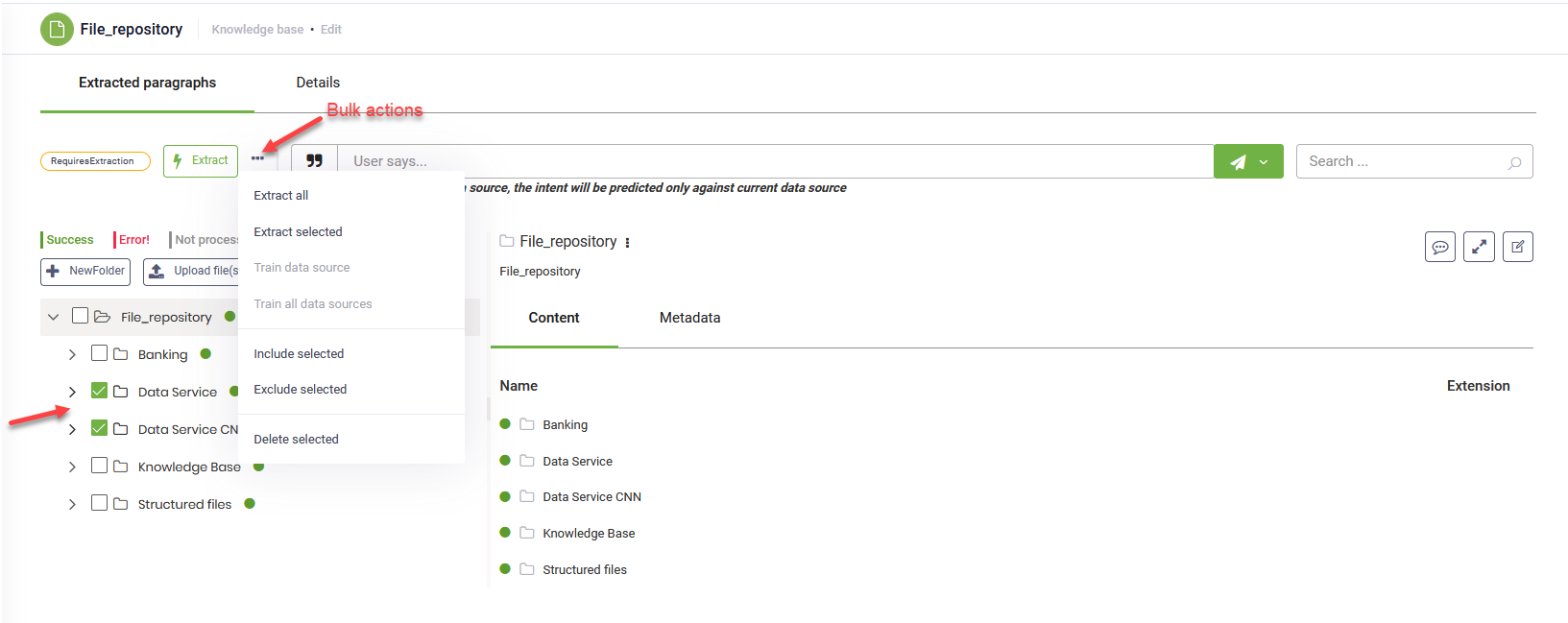
The sections below provides an overview of bulk actions you can perform based on the above mentioned criteria.
File repository
| Action | Status | |||||||
|---|---|---|---|---|---|---|---|---|
| New | Requires Extraction | Extracting | Extraction Failed | Requires Training | Training | Training Failed | Trained | |
| Extract All | ||||||||
| Extract Selected | * | * | * | * | * | |||
| Train Data Source | ||||||||
| Train All Data Sources | ||||||||
| Include selected | * | * | * | * | * | |||
| Exclude selected | * | * | * | * | * | |||
| Delete selected | * | * | * | * | * | |||
Legend
- green - the action is available.
- red - the action is not available.
- * The action is available only when you select the check box for at least at least one element in the tree explorer.
Website, SharePoint, Network shared drive
| Action | Status | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| New | Requires Crawling | Crawling | Crawling Failed (Warning) | Requires Extraction | Extracting | Extraction Failed | Requires Training | Training | Training Failed (Error) | Trained | |
| Extract All | |||||||||||
| Extract Selected | * | * | * | * | * | * | |||||
| Train Data Source | |||||||||||
| Train All Data Sources | |||||||||||
| Include selected | * | * | * | * | * | * | * | ||||
| Exclude selected | * | * | * | * | * | * | * | ||||
| Delete selected | * | * | * | * |
*
|
||||||
Legend
- green - the action is available.
- red - the action is not available.
- * The action is available only when you select the check box for at least at least one element in the tree explorer.
Bulk actions definition
The table below provides a short description of all bulk actions.
| Bulk action | Description |
|---|---|
| Crawl all | Identifies all the hyperlinks in the retrieved web pages from the given Content Location (URL) / website / Uri. |
| Crawl selected | Identifies all the hyperlinks in the web pages selected in the tree explorer. |
| Extract unprocessed |
Extracts all data that has not been processed or failed extraction. NOTE: The action is available at the data source level and for root and node elements.
|
| Extract all | Extracts all data from the current data source, including processed data. |
| Extract selected | Extracts data only from the elements selected in the tree explorer. |
| Train data source | Trains only the current data source. |
| Train all data sources | Trains all data sources in the Knowledge Base. |
| Include selected | Includes only the elements selected in the tree explorer in the extraction / training. |
| Exclude selected | Excludes the elements selected in the tree explorer from the extraction / training. |
| Delete selected | Deletes the selected elements from the tree explorer. |